最近在公司的服务器监控中发现许多机器的I/O利用率很高,甚至触发了告警阈值。
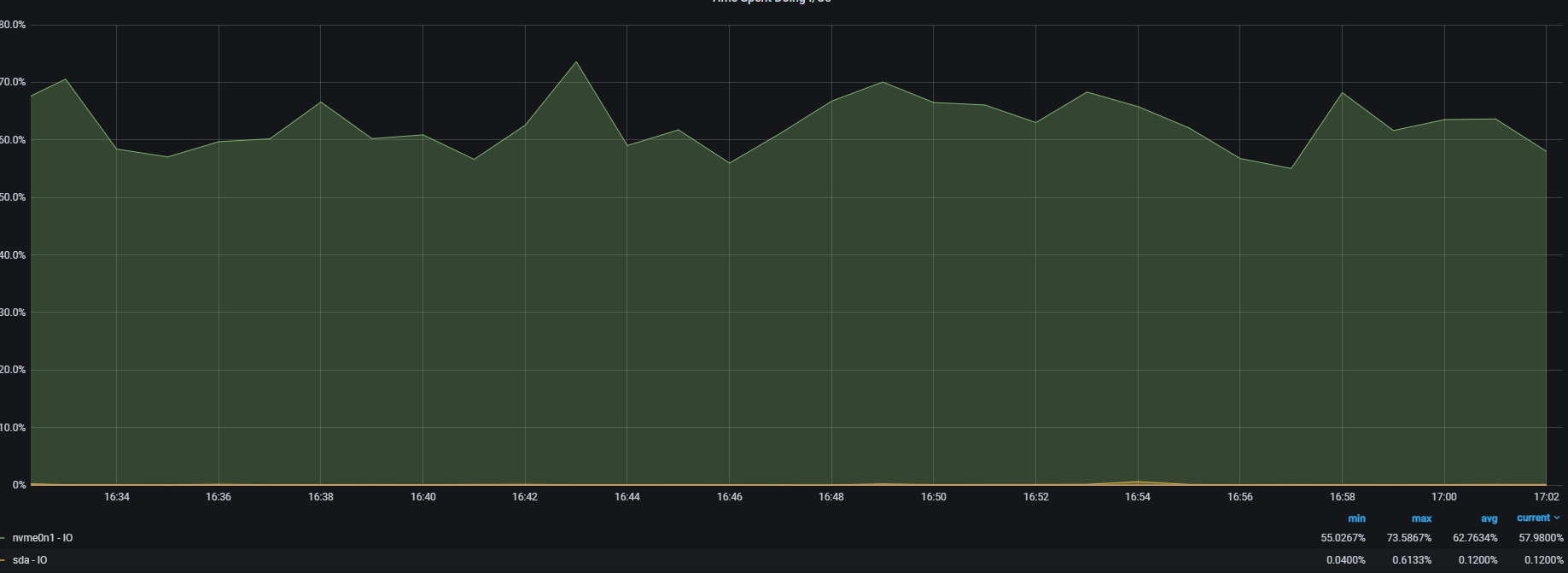
然而,登录机器上看并没发现有什么业务进程持续产生大量读写,通过iostat -mtx 2命令看,机器的的确没啥读写,但%util指标却一直会比较高
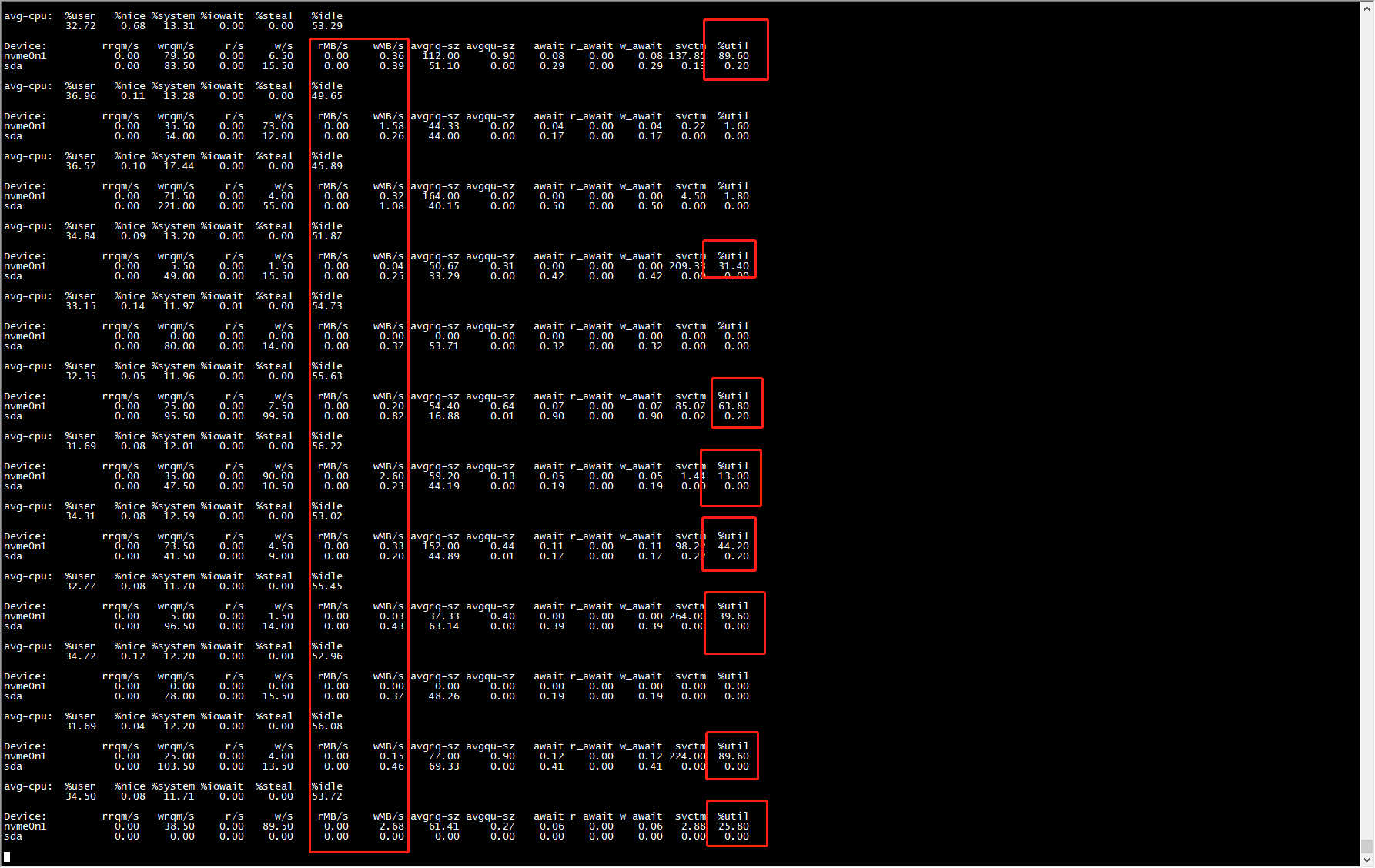
通过查阅资料发现,这是4.19内核普遍存在的Bug#927184,对于ssd设备,系统在/proc/diskstats上报的数据失准了。而iostat命令的util指标就是来自于diskstats中的io_ticks字段值。除了升级内核外,找到一个临时的解决办法,通过修改I/O
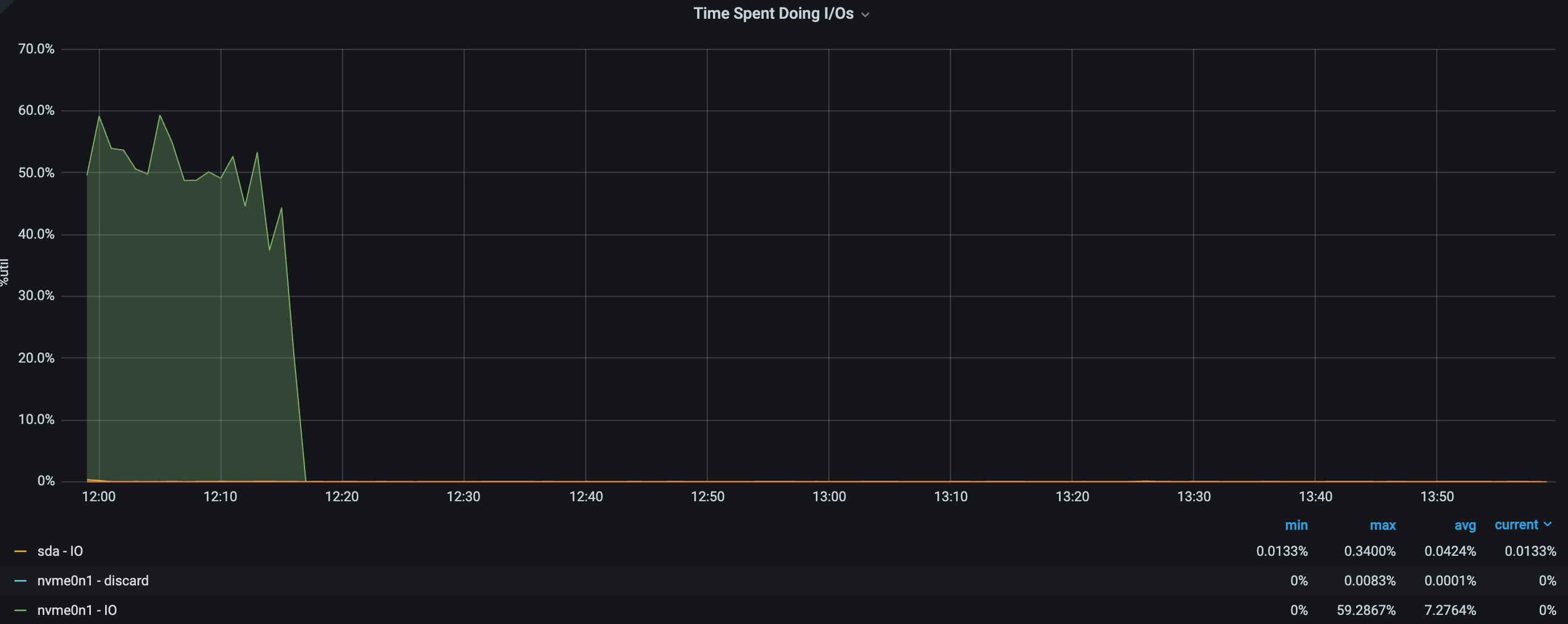
scheduler参数,设成mq-deadline。通过对比测试,发现的确是有效果(见下图)。相较于默认的IO调度器,mq-deadline在大部分性能指标下有所下降,但幅度也很小(参考Benchmark)
,相信这个差异对于大多业务也未必感觉得到。
后续进一步参考了解%util指标的细节,发现这是一个很容易让人产生误解的参数,它并不完全是字面意义上的磁盘利用率,即使%util达到了100%,也并不表示磁盘设备饱和了,无法处理更多的IO请求。首先%util指标就是来自于diskstats中的io_ticks字段值,这个值并不关心等待队列里IO的个数,它只关心队列中有没有IO。
最简单的例子是,某硬盘处理单个IO请求需要0.1秒,有能力同时处理10个。但是当10个请求依次提交的时候,需要1秒钟才能完成这10%的请求,,在1秒的采样周期里,%util达到了100%。但是如果10个请一次性提交的话,
硬盘可以在0.1秒内全部完成,这时候,%util就只有10%。
因此,在上面的例子中,一秒中10个IO,即IOPS=10的时候,%util就达到了100%,这并不能表明,该盘的IOPS就只能到10,事实上,纵使%util到了100%,硬盘可能仍然有很大的余力处理更多的请求,即并未达到饱和的状态。
那么有没有一个指标用来衡量硬盘设备的饱和程度呢。很遗憾,iostat没有一个指标可以衡量磁盘设备的饱和度。
